File Systems
- A pattern to the arrangement of data on a disk
- Have a mounting scheme
- Usually involve a naming and directory system
- Other possible features
- Redundancy
- Networking
- In modern systems, the operating system is an intermediary between the process and the disk
Files
- Logically named persistent storage
- Can be stored as a byte sequence or a record sequence (a record is just multiple bits)
- Also a paradigm for I/O devices, communication
- File Type
- Determined by
- extension
- magic numbers (signature at start of file)
- file attributes (metadata)
- look at file contents
- Determined by
- File Control Block
- Attribute and location information of a file
- Called a file descriptor when loaded into memory
- Distributed across the file system (within directories or reachable with them)
- File Operations
- Can be accessed sequentially or via random access depending on the media type
- Sequential Access
- Tapes, Pipes
- Must be accessed/navigated in linear order
- Some but not all can rewind
- Random Access
- HDD, SSD, Floppy
- Data can be accessed in any order
- Shared Files
- Regular/Hard Links
- Holds reference to inode of the target file
- Works only within the same file system
- Removing any link doesn’t affect other links
- Cannot be used with directories
- Symbolic/Soft Links
- Holds path to the target file, not the contents
- Can link to a directory
- Can link across different file systems
- If the original file is deleted or moved, the links will not work correctly
- Regular/Hard Links
- When links to a file hits 0, it is considered deleted
Directories
- A special file type that holds part of the file control block about other files
- Implementation
- Normal list (hard to keep sorted for efficient search)
- Linked List (easier to keep sorted but link overhead)
- B+ Tree (actually used)
- Hash Table (typically used alongside a linear structure)
- Names
- Windows
- FAT32: Stores all the metadata in 28 out of 32 of the file block
- Virtual Fat
- A way of tacking longer names onto FAT32
- Has a long entry that connects to a base entry that supports longer names
- UNIX
- INODE links to a name entry that contains 255 bytes for the name
- Windows
Mounting
- We mount a file system to make it accessible to programs through the operating system
- During the boot process, the root filesystem gets mounted
- Its information is added into a mount table structure
- The file system may be checked for errors or inconsistencies
- Filesystems may be mounted either automatically or manually
Linux Virtual Filesystem (VFS)
- With VFS, most userspace programs are written filesystem agnostic
- Sandwiched between two layers
- Upper: system call layer
- Lower: set of function pointers (one per filesystem implementation)
- Implementation
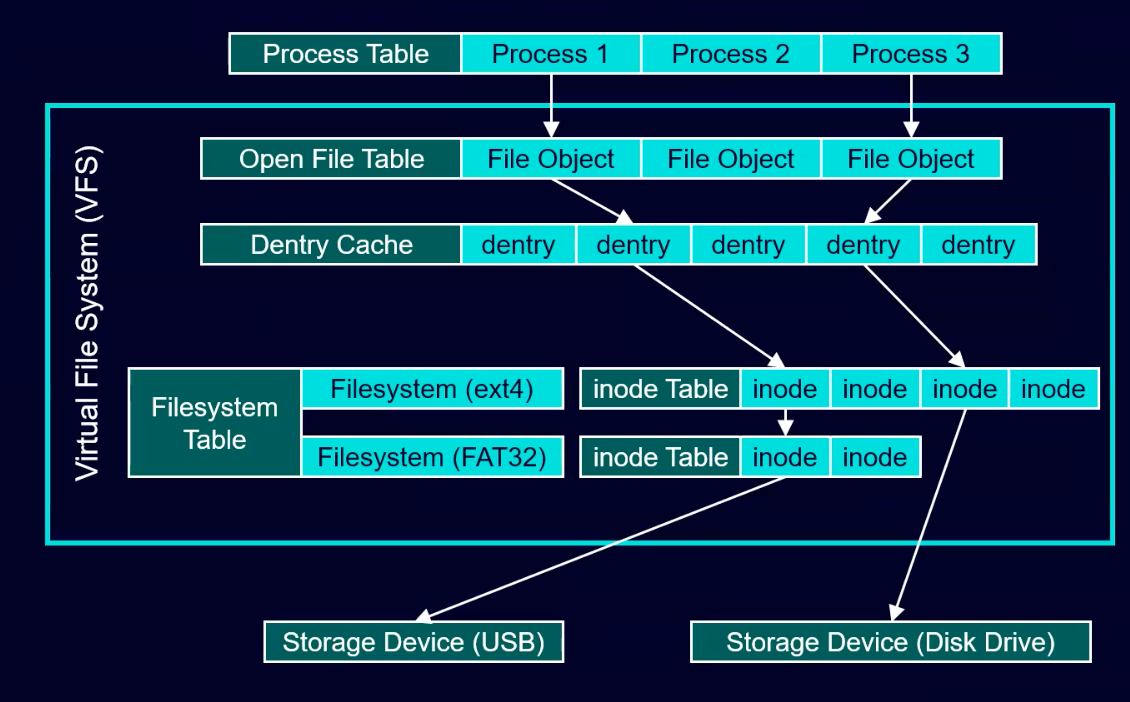
- File Objects
- Represents an open file
- Contains data such as flags used while opening the file and the offset from which a process can read or write from
- Directory Entries (Dentries)
- Holds inodes and files objects together
- Contains names or identifiers
- Exists for both files and directories
- Filesystem Type
- In order to use a filesystem, the kernel must know the filesystem type
- Filesystems types must be registered
- Once registered, a filesystem of that type may be mounted
- Inodes
- File data structure that stores information about the file
- Does not include name (in directory entry) and data (in block that it points to)
- Superblock
- Structure that represents an instance of a filesystem
- Typically stored on the storage device itself and loaded into memory when mounted
File Allocation
-
Operating systems often use multiple methods depending on what is most efficient for a particular file
-
Contiguous (all in a row)
- Files are stored purely in order on the drive
- Performance is good
- May have external fragmentation
- Problems when file grow or the exact size is unknown at creation time
-
Linked List (block)
- Each block holds a pointer to the next
- Prevents external fragmentation
- Inefficient random access
- Storage must be used for each link (can group blocks to reduce this)
-
Chained table (FAT)
- File allocation table
- Statically allocated at time of formatting
- Chain store the linked list as a table in memory to minimize disk access
- File points to the first index in the table, which points to the next block for that file. Continues until it hits the end
- A single point of failure
- Usable disk size is limited by the size of the table
- File allocation table
-
Indexed allocation (index nodes)
- Stores locations of each block for a file in a single index block referenced by the file control block
- If an index block breaks, only that one file is lost
- Limit for file size is how many blocks the index block can contain
-
Multi-level indexed allocation (tree structure)
- Use direct and indirect blocks to increase maximum file size
- The index block points to more index blocks which eventually point to the file blocks
- Supports big files but wastes space on small files
-
Chained indexed allocation (index + linked list)
- use direct blocks with an additional indirect pointer to the next index
- Primary index block contains a link to the next index block and it continues for as long as needed
- Allows for small files not to waste space
-
Combined
- Supports jumping to small files directly (efficient because most files are small)
- Index blocks are used when needed
- Index blocks can also contain other index blocks when they are needed (but as a full tree instead of a single linked list of index blocks)
- Used in unix systems
Blocks
- Unit of allocation on the disk (like pages in memory)
- Size
- Trade-off between disk utilization and data transfer rate
- Bigger: better data rate but possibly worse disk utilization (fragmentation)
- Smaller: more time spent seeking, leaking to lower data rate, but better disk utilization
- Tracking free blocks
- Free blocks form a linked list
- Problem: Writing and deleting a file rapidly can cause thrashing (frequently copying to memory)
- Solution: Keep multiple blocks loaded into memory
- Free blocks form a linked list
- File System Consistency
- Systems unexpectedly shutting down could cause an inconsistent state
- Check using a block consistency checker
- Types of problems
- Missing block (block that is not used is not marked as free)
- Update the free block tracking based on what files say they are being used
- Duplicate block in free list (block is found twice in the linked list)
- Bring it down to one
- Duplicate data block (two files are referencing the same data block)
- No easy solution. Split the files into separate blocks and then have the user check. Might save one.
- Missing block (block that is not used is not marked as free)
Reliability
- Backup Types
- Physical Dump
- Copy everything, exactly as it is stored on the disk
- Very simple to implement
- Runs very fast
- Inefficient
- Logical Dump
- Starts at a directory
- Dumps all the files which changed since the last backup
- Used by most UNIX systems
- Physical Dump
- Resiliency
- Mirrored storage
- Every write is duplicated
- Reads are to whichever system is last loaded
- Automatic failover when disk, file system, or network fails
- Redundant Arrays of Independent Disks (RAID)
- Why
- A way of storing the same data in different places on multiple drives
- Provide performance gains through parallel hardware access
- Provide reliability through redundant storage
- Fast recovery
- Hot swap is possible
- Can be software or hardware based
- Types
- RAID 0 (Data Stripping)
- Splits files into blocks and scatters them across physical storage units
- Increases overall performance due to higher cumulative throughput
- Offers no data redundancy
- RAID 1 (Data Mirroring)
- Mirrors data between two drives
- RAID 2 (Bit Stripping)
- Stripes data at the bit (rather than block) level
- Rarely used in practice
- Could get very high data transfer rates in multiple magnetic disks spinning at the same rate
- RAID 3 (Byte Stripping with Parity Disk)
- Parity disk is an error recovery disk
- Can lose one disk
- Cannot service multiple requests simultaneously (any single block of data is spread across all members of the set)
- Rarely used in practice
- Parity disk is an error recovery disk
- RAID 4 (Block Stripping with Parity Disk)
- More often used because can support multiple requests at once
- Random writes are slow because each one has to update the parity on the same disk
- RAID 5 (Block Stripping with Distributed Parity)
- Parity information is distributed among the drives
- Requires at least 3 disks
- Makes random writes faster because the parity disk is no longer a bottleneck
- RAID 6 (Block Stripping with two distributed parity blocks)
- High fault tolerance: allows losing two drives
- Slow rebuild time because it has to check parity across all drives
- RAID 0 (Data Stripping)
- Why
- Journaling
- Keeps track of changes not yet committed to the file system
- Records the goal of such changes in a data structure known as a journal
- Uses for systems with sensitive data
- Costly in speed and storage
- Mirrored storage
Kernel Data Structures
- File Descriptor Table
- Stores pointers to the corresponding entry for a file in the file table
- Opening a file returns an index in this table if the file successfully opens
- Per process
- File Table
- Currently open files
- Stores flags (R, W, …), offset within the file, refcount
- Points to Inode table
- Can have multiple entries for a single file (if open is called on that file multiple times)
- System wide
- Inode Table
- Permanent information
- Stores metadata like size, type, etc.
- System wide
- This is not the file system inode table, an in memory representation for all the file systems (with only the relevant files populated)
Relevant System Calls
open- creates a new entry in the file descriptor table and the file table
close- delete a file descriptor, decrementing refcount of the associated entry in the file table
write- writes to a buffer cache
- the kernel then later initiates a write to the actual device (
fsync)
dup- creates a new file table entry for the file the provided file id is for (incrementing that file’s refcount in the file table)
dup2(oldfd, newfd)replacesoldfddescriptor with a new one that points to the file ofnewfd(closingoldfdin the process)
int pipe(int fd[])- Pipes are special files that are actually a shared memory buffer managed by the kernel
- One “file” for read, one for write.
fd[0]is the read end,fd[1]is the write end reada pipe returns 0 (end of file) when there are no write ends open (the refcount of the write end in the file table) and there is no data left in the pipe buffer- It is best practice to only have one read end and one write end, though you can have multiple by forking (which creates a new file descriptor table and increments the refcounts)
IO Buffering
- Types (and default use)
- Line buffered (stdout, stdin)
- Not buffered (stderr)
- Block/Full buffered (files)
- Can set the buffer with
setvbuf(FILE* fp, char* buf, scheme, size)setbuf(FILE* fp, char* buf)NULLfor not buffered, full buffered with size ofchar*otherwise
- Note: set the buffer to something in the data segment, locally initializing something (even if it is in main) will not live long enough because it needs to live past exit
printfuses a userspace buffer that only executes write toSTDOUTwhen there is a linebreak (to run fewer syscalls)- mixing
printfandwrite(STDOUT_FNO, ...)could lead to unintuitive behavior if they don’t all end with newlines because they would be writing to different buffers
- mixing
- When
stdoutis redirected to a file, the buffering scheme is changed to block buffering so behavior of what is ultimately written might change