Cache
- Level of memory closest to the CPU
- Optimizes for the principle of locality
- How we know what memory is currently stored in the cache
- Store the block address as well as the data
- Tag
- Index
- Implicitly stored in the row of a direct cache
- Offset
- Bits at the end of the address that are implicitly remembered
- Two Parts
- (2^number of offset bits) bytes will be returned by a single memory access
- Since memory is in multiples of 4, you don’t need to remember the last 2 bits in 32 bit systems because it will always be 00
- Since memory is in multiples of 8, you don’t need to remember the last 3 bits in 64 bit systems because it will always be 000

Types
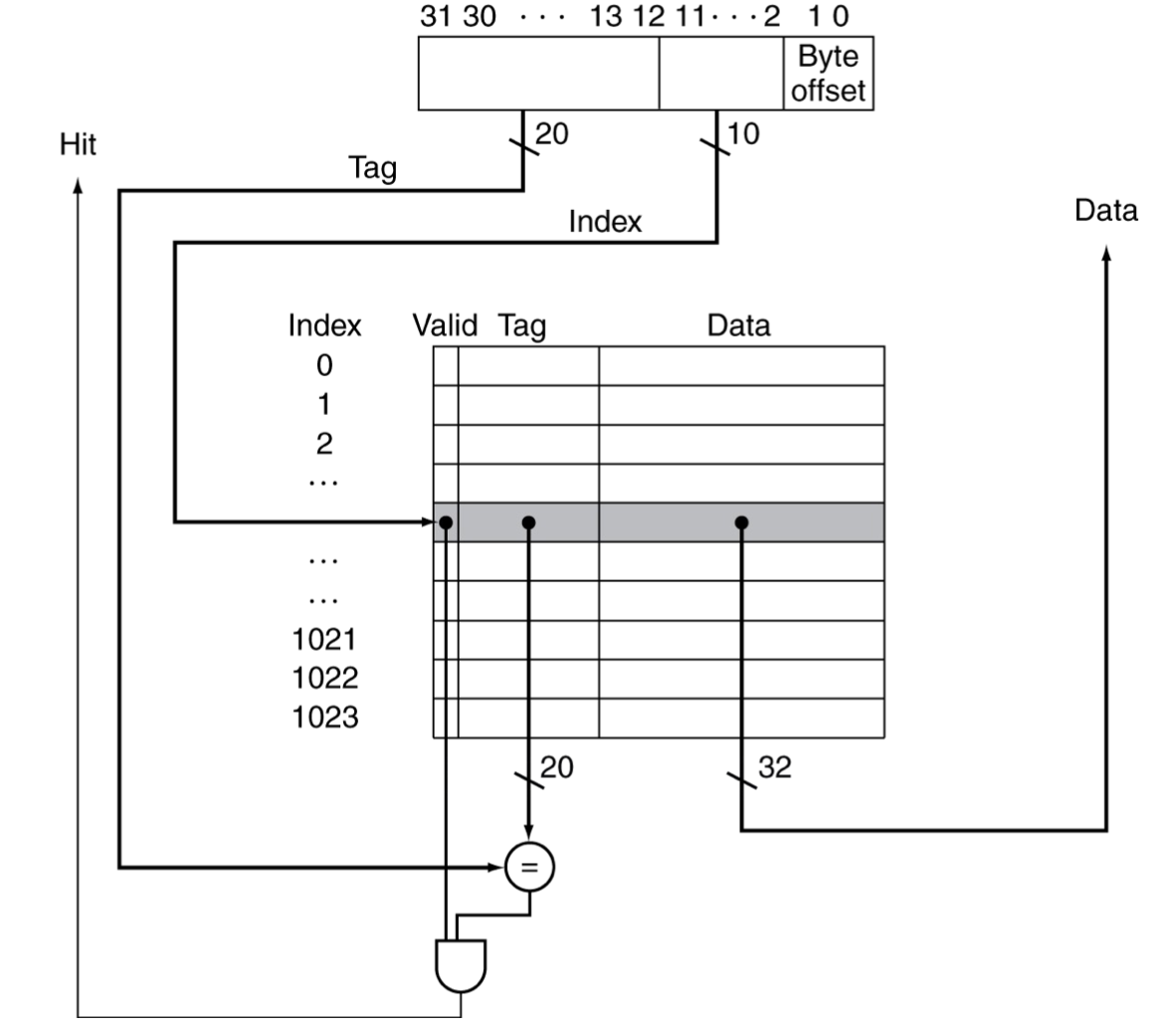
- Direct Cache
- Structure
- The last n bits of the address (excluding offset) are implicit based on the row of the cache
- the number of rows in the cache are 2n
- The rest of the address is stored in the tag
- Valid bit which is 1 when data is stored in the location
- When accessing
- Take the last n bits of the access address, and go to that row of the cache
- Check that the valid bit is 1
- Check that the rest of the bits of the access address matches the tag at that row
- If they match, then the cache is storing data for that address
- Problem: certain code can create lots of conflicts if different addresses with the same last three bits are accessed in a loop
- Fully-Associative Cache
- Structure
- Store the data anywhere
- Store the entire address (excluding the offset) in the tag
- Tradeoff
- Reduce the number of conflicts
- Tags are larger
- Linear lookup time which can be parallelized into constant but it would be very expensive to do so
- Set-Associative Cache
- Combination of the other two
- Structure
- Create multiple direct caches
- the number of caches → n-way name
- 0-way = direct cache
- n-way = fully associate cache
- When adding, pick a way using a method and then add to that one like a normal direct cache
- Least Recently Used (LRU): Choose the way that was written to the least recently
- Pick randomly
- Accessing
- Check all ways to find the matching row if it exists

- Typical Usage
- L1: Direct Access
- L2: Set associative
- Main memory: fully associative (not a cache but accessed in the same way)
- Finding the index number fast
- divide and then use modulo
- #todo
Blocks
- We can store multiple words data in one row of the cache
- Need to adjust offset so any address in the same block points to the same row in the cache
- Optimizes for spatial locality
- When putting data into the cache, also put nearby data into the cache (the block)
- Size considerations
- But in a fixed-sized cache, larger blocks → space for fewer blocks
- That means you override more with each load, which can negatively affect temporal locality
- There is a balance that optimizes both depending on the size of the cache, found experimentally
Misses
- On hit, the CPU proceeds normally
- On cache miss
- Stall the CPU pipeline
- Fetch block from next level of hierarchy
- Instruction cache miss → Restart instruction fetch
- Data cache miss → Complete data access
Writing
- Write-Through
- So that when you write to L1, write to all the other caches
- This is very resource intensive, so it is not often used
- Write-Back
- On data write hit, just update the block in the cache
- Keep track of which blocks have been written to (dirty block)
- Only write back to lower caches when those lower caches are needed
- Write Allocation
- For what should happen on write miss
- Write-Through
- Allocate on miss: fetch the block
- Write around: don’t fetch the block
- Write-Back
Instruction vs Data Caches
- Instructions and data have different patterns of temporal and spatial locality
- Also instructions are generally read-only
- Can have separate instruction and data caches
- Advantages
- Doubles bandwidth between CPU and memory hierarchy
- Each cache can be optimized for its pattern of locality
- Disadvantages
- Slightly more complex design
- Cannot dynamically adjust ratio taken by instructions and data
- 100% of instructions will access the instruction cache
- Components of CPU Time
- Program execution cycles (includes cache hit time)
- Memory stall cycles (mainly from cache misses)
- With simplifying assumptions:
Memory stall cycles=programmemory accesses⋅miss rate⋅miss penalty=programinstructions⋅instructionmisses⋅miss penalty
- Average memory access time (AMAT)
- Hit time + (Miss rate * Miss penalty)
- Access time of L2 from the perspective of L1
- L1 Miss penalty + (L2 Miss rate * L2 Miss penalty 2)
- Overall Cycles Per Instruction (CPI)
- Remember that 100% of instructions will access the instruction cache
Types of Misses
- Compulsory
- The first time you access an address, it will not be the cache
- Unless it was pre-fetched
- Capacity
- The working set of blocks accessed by the program is too large to fit in the cache
- Conflict
- When a block is evicted to early because it was replaced
- Does not happen with fully associative caches
- When confused about capacity vs conflict you can go “would this still happen if fully associative” and if the answer is no then it is a conflict miss
- Coherence
- Only for multicore systems
- When a different processor has modified a value that is also stored in the processor’s cache
Interactions with Software
- Misses depend on access patterns
- Algorithm behavior
- Compiler optimization for memory access
- The cache can be populated by inserting loads to
XZR