Pipelining
- Instruction level Parallelism which overlaps the execution of instructions
- Increases throughput of many operations instead of latency of individual operations
Motivation
- In early CPUs, deep combinational logic networks were used between state updates
- Signal delays may vary widely between paths
- New input cannot be processed until the slowest path has finished
- → slow clock speeds → slow processing rates
Design
- Logic networks are divided into shallow slices (pipeline stages)
- Delays through the network are made uniform (faster stages are slowed down)
- The clock cycle can be set to the slowest path within the slowest slice
- → A new input can be provided to each slice as soon as its quick shallow network has finished
- Slows down the actual operations, but allows operations to overlap
- These is a tradeoff that needs to be balanced
- In addition, stabilizing the data between the stages takes time too
LEGv8 Pipeline
- Five stages, one step per stage
- IF: Instruction fetch from memory
- ID: Instruction decode and register read
- EX: Execute operation or calculate address
- MEM: Access memory operand
- WB: Write result back to register
- Visualization
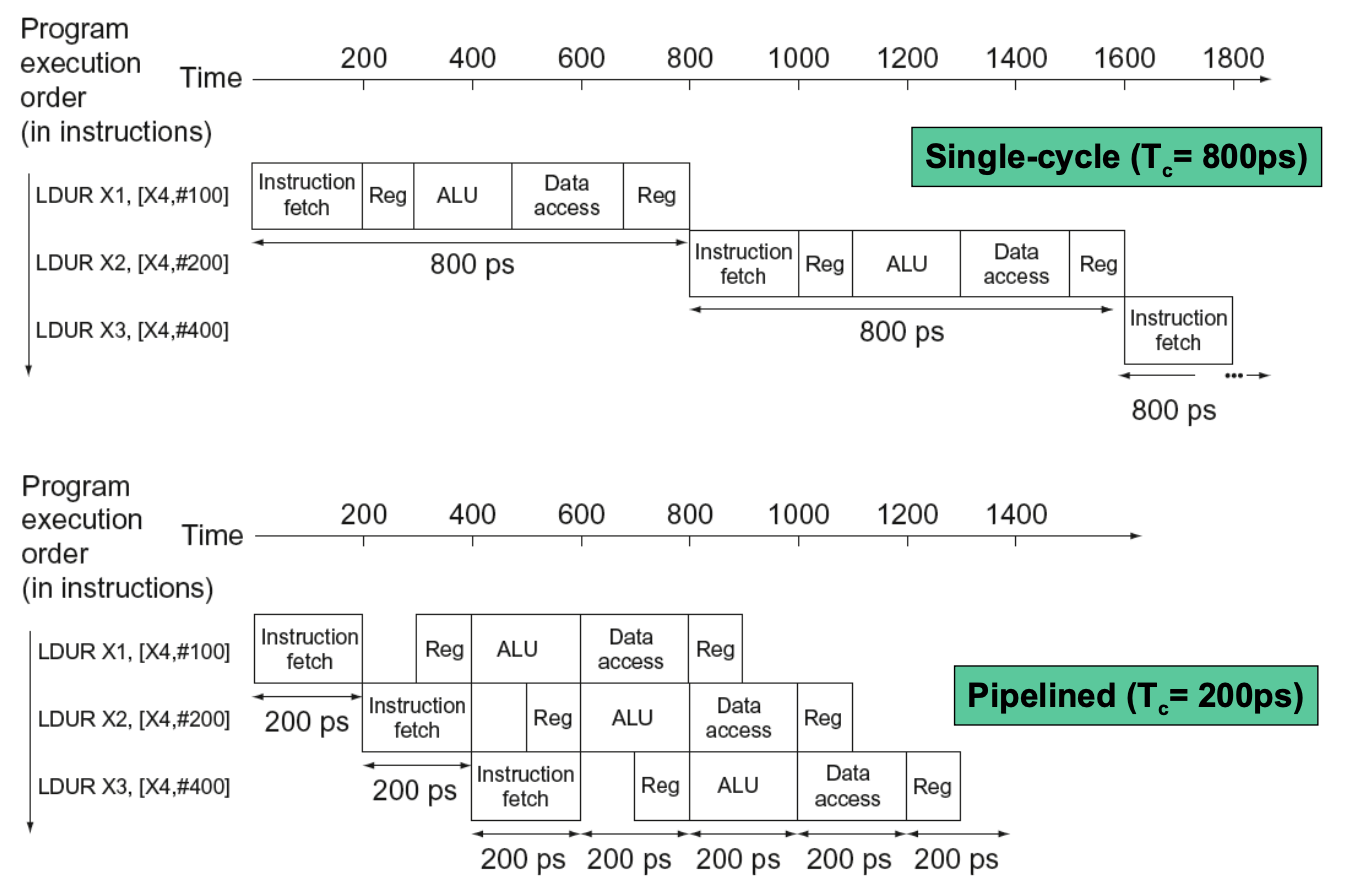
- Note: Register reads and write happen in half of a clock cycle (write first, read second)

- Dark shade means used, no shade means not used
- Shade in the left for WB means the writing is performed in the left half of the clock
- Shade in the right of IF and ID means instruction memory and register are read in the right half of the clock
Speedup
Sk=k+(n−1)nk
- k stage pipeline, n instructions
- ≈k when n>>k
- Related Terms
- Clock Period: τ = Max time delay of a stage + other delay (eg. skew, latch delay)
- Efficiency: η=Sk/k
- Ratio of its actual speedup to the ideal speedup
- Throughput: w=η/τ
- #question does instructions mean instructions per pipeline or overall count
Delays